LifeSciBench: OpenAI’s Hard New Life-Science Benchmark — and How GPT-Rosalind Stacks Up
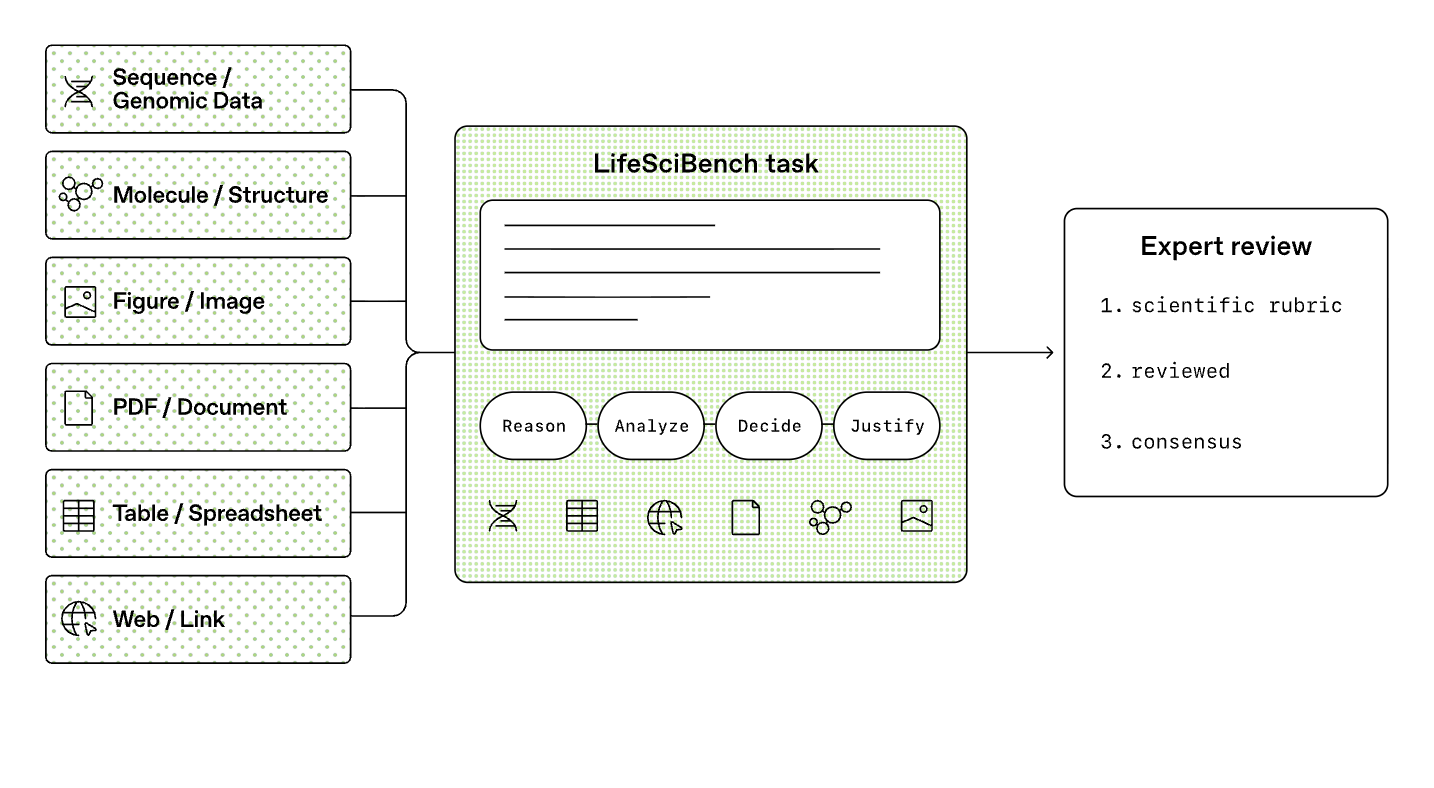
OpenAI just released LifeSciBench, a 750-task, expert-written, expert-reviewed benchmark that tries to measure whether AI can actually do real life-science research work — not just answer biology trivia. Here’s what it measures, how its new GPT-Rosalind model compares to GPT-5.5 and rivals, and where it sits against the other serious life-science benchmarks like LAB-Bench, BixBench and BiomniBench.
LifeSciBench is meant to be an evaluation tool built to test AI systems on the messy, judgment-heavy work that actually fills a scientist’s day: interpreting incomplete evidence, reconciling conflicting results, designing experiments, troubleshooting assays, weighing translational risk, and deciding what to do next under uncertainty.
The headline numbers:
- 750 expert-authored tasks, spanning seven research workflows and seven biological domains.
- Built by 173 PhD-level scientist contributors with biotech/pharma experience, graded against 19,020 rubric criteria (≈25 per task), and validated by 453 independent expert reviewers.
- The new GPT-Rosalind model lifts the overall exact pass rate to 36.1%, up from 25.7% for GPT-5.5 — real progress, but a long way from saturation.
The strategic subtext: LifeSciBench is OpenAI’s measuring stick for its own life-sciences model line. It’s the most rigorously constructed life-science benchmark yet — and also one that OpenAI built, ran, and used to showcase its model, which is exactly why the caveats matter. We covered the model itself when OpenAI entered the AI-bio arms race with GPT-Rosalind; LifeSciBench is the scorecard that comes with it.
What LifeSciBench actually measures
Most science benchmarks test knowledge — textbook recall, multiple-choice questions, clean reference answers. LifeSciBench’s whole premise is that real research rarely looks like that. To define its taxonomy, OpenAI surveyed practicing scientists about the workflows they use most, then grouped the answers into seven recurring categories:
| Workflow | What it tests |
|---|---|
| Evidence handling | Extracting, reconciling, and auditing evidence from papers, figures, tables, records |
| Analysis | Working through data to reach defensible conclusions |
| Design, optimization & prediction | Designing experiments, constructs, and assays |
| Scientific reasoning | Reasoning from evidence shown in the moment, not just recall |
| Validation & operations | Practical lab realities — troubleshooting, QC, operational constraints |
| Translation | The “bench-to-bedside” link from preclinical evidence to clinical implications |
| Scientific communication | Organizing evidence into convincing, expert-facing explanations |
Each task is framed like a request to a knowledgeable collaborator: a scientific prompt, any relevant context or data files, and a free-response answer (no multiple choice). The design is deliberately hard:
- 79% of tasks require multiple reasoning or decision steps (about four steps on average).
- 53% require interpreting or synthesizing at least one artifact — and there are 1,062 attached artifacts in total: figures, PDFs, tables, sequence files, structure/chemical files, and web references.
This is the deliberate opposite of a trivia test. It’s an attempt to grade research judgment.
The rubric is the innovation
The cleverest part is the grading. Each task carries a detailed, task-specific rubric that decomposes the expected answer into individual claims, calculations, decisions, justifications and caveats — 19,020 criteria across the benchmark, ~25 per task. That captures something a final-answer check can’t: a response can reach the right top-line conclusion but still be marked incomplete if it misses a key assay limitation, or earn meaningful credit for strong partial reasoning even when it doesn’t fully solve the task.
OpenAI reports two metrics accordingly: Pass rate (the share of tasks where a model clears a 70% success threshold) and Score (average rubric reward, i.e. partial credit). Both matter, because scientific usefulness isn’t binary.
Rubrics were written according to the following principles:
- Specificity: each criterion should describe a concrete property of the response.
- Atomicity: each criterion should evaluate a single claim, calculation, decision, or constraint.
- Evaluability: criteria should be answerable as satisfied or not satisfied from the model response
alone. - Grounding: criteria should be supported by the task prompt, provided artifacts, accepted
scientific facts, or expert consensus. - Non-redundancy: criteria should avoid double-counting the same requirement unless the
repeated criterion captures a distinct aspect of the response. - Operational usefulness: rubrics should reward responses that are not merely correct in
isolation but useful for the scientific decision posed by the task.
A taste of the difficulty
One published example asks the model to pressure-test a clinical data package for a Duchenne muscular dystrophy AAV9 micro-dystrophin gene therapy heading into an FDA Type B meeting — item by item, the way a skeptical regulator would. A strong answer has to catch things like an antibody epitope that can’t distinguish the transgene from revertant dystrophin, the invalidity of quantifying a truncated construct against a full-length standard, the confounding of an external natural-history control versus a randomized one, and the mechanistic ceiling created by deleting nNOS-binding spectrin repeats. That’s not recall — it’s the kind of multi-disciplinary teardown a senior translational scientist does, and the rubric rewards exactly those specific catches.
How seriously it was built
The construction rigor is the benchmark’s strongest selling point. Accepted tasks averaged six automated review cycles plus at least two rounds of expert review, with ≥90% reviewer agreement required. Validation came from 453 reviewers who didn’t write the tasks — 97% holding a PhD or equivalent, averaging 12 years of experience and 14 publications — and agreement that tasks reflected real research, tested the right skills, and were properly grounded exceeded 96% in every category. By the standards of AI-for-science evals, that’s an unusually heavy human-expert investment.
The results: GPT-Rosalind vs GPT-5.5 (and the field)
LifeSciBench launched as the showcase for GPT-Rosalind, OpenAI’s first purpose-built life-sciences model (named after Rosalind Franklin). The comparison against its general-purpose predecessor, GPT-5.5, is the core story.
Where the new model gains
| Metric | GPT-5.5 | GPT-Rosalind |
|---|---|---|
| Overall exact pass rate | 25.7% | 36.1% |
| Scientific Communication (n=9, interpret cautiously) | 56.3% | 71.1% |
| Translation | 36.8% | 57.7% |
| Expert-useful / actionable outputs (rubric-level) | 29.1% | 44.7% |
| Uncertainty & caveat handling (rubric-level) | 29.3% | 44.8% |
The pattern is consistent: GPT-Rosalind is strongest where the task has a clear evidence boundary and calls for structured scientific judgment — synthesis, communication, translating preclinical evidence to clinical implications, and being appropriately careful with uncertainty.
Where everything still falls short
The honest part of OpenAI’s writeup is how much is not solved:
- Design, Optimization & Prediction: 30.7% — one of the hardest workflows.
- Analysis: 30.3% — similarly weak.
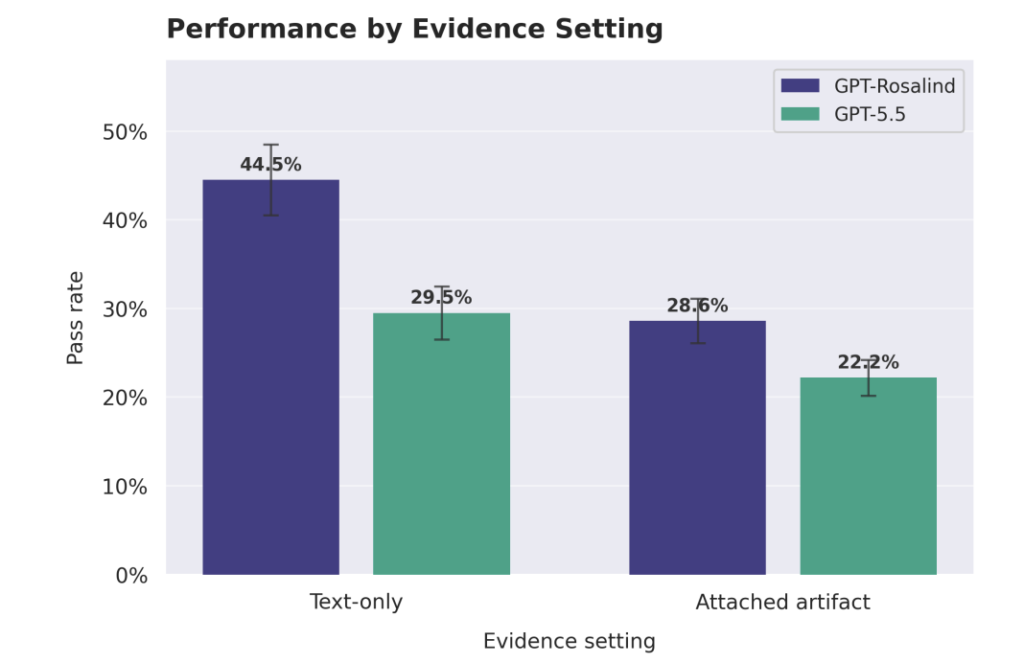
- Artifact use is the clearest bottleneck. GPT-Rosalind drops from 45.1% on text-only tasks to 28.1% when a task requires reading figures, large sequence files or URLs. GPT-5.5 shows the same collapse (29.9% → 21.9%). Models still struggle to pull information out of complex figures and big sequence files and fold it into an answer.
- Exact-output tasks are brittle: 14.8% on numeric tasks, 24.0% on sequence/structure outputs, 27.3% on construct generation — with little improvement over GPT-5.5. That matters because real workflows (CRISPR/HDR donor design, siRNA design) need outputs exact enough to use directly.
- Partial-but-failing is common: in ~14% of tasks, models earned substantial rubric credit while missing the pass threshold. For GPT-Rosalind, 109 tasks scored under 20% pass yet earned at least 50% rubric reward — relevant evidence found, plausible partial answer, but a key constraint missed or the reasoning not connected to a usable decision.
The competitive read OpenAI buried
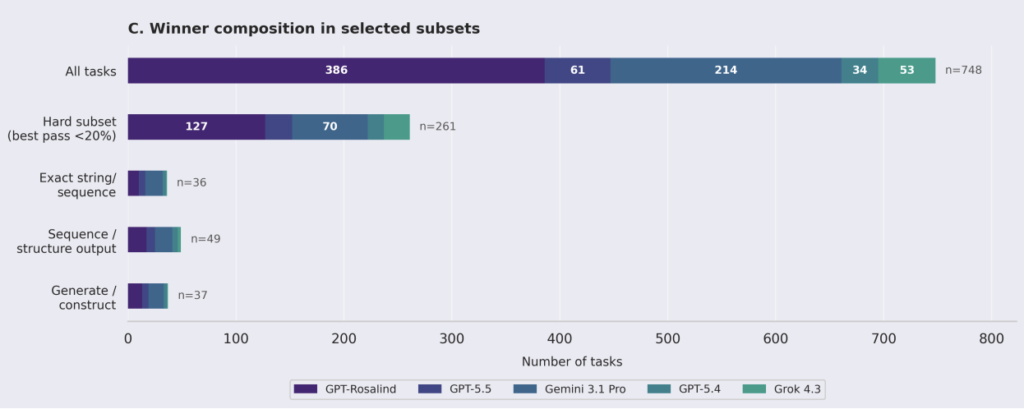
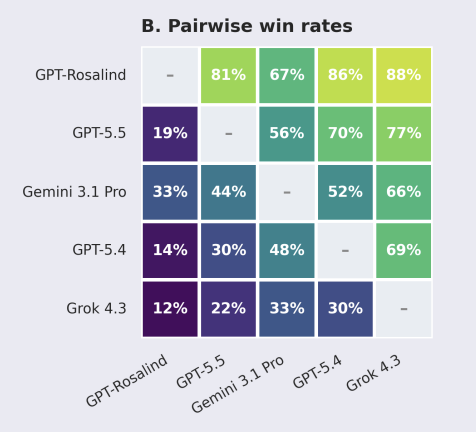
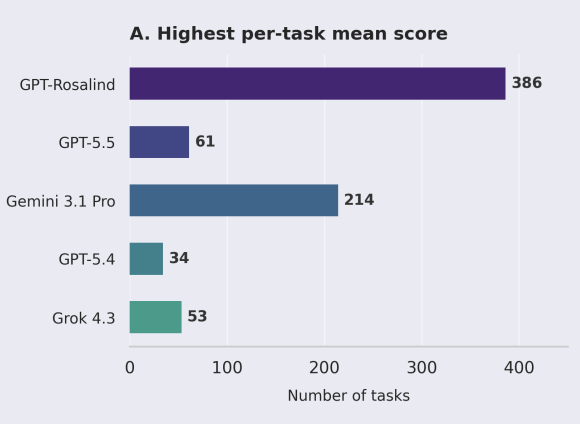
This is the detail every critical reader should note: GPT-Rosalind led overall, but on a single-turn evaluation with open internet browsing, it uniquely topped only 386 of 750 tasks, while Gemini 3.1 Pro uniquely led on 214. Grok 4.3 was also in the field. So the “GPT-Rosalind wins” framing is real but narrow — a plurality, not a rout, with Google’s model winning a large minority of tasks outright. And conspicuously, Anthropic’s Claude models were not included in the comparison at all — a notable omission given Claude’s heavy use in scientific tooling like Claude Scientific Skills.
GPT-Rosalind in context: the model lineage
To read LifeSciBench fairly, it helps to know where GPT-Rosalind sits in OpenAI’s fast-moving life-sciences push — a campaign we’ve tracked since its arms-race debut.
| Milestone | Date | What it added |
|---|---|---|
| GPT-Rosalind launch | Apr 2026 | First purpose-built life-sciences reasoning model; partners Amgen, Moderna, Allen Institute, Thermo Fisher |
| GPT-5.5 base | Apr 23, 2026 | The agentic coding + tool-use foundation GPT-Rosalind builds on |
| Rosalind Biodefense | May 29, 2026 | Security-focused variant |
| June update | Jun 3, 2026 | Deeper medicinal chemistry + genomics, fewer tokens, global research preview; Novo Nordisk added |
| LifeSciBench | Jun 17, 2026 | The externally-judged benchmark used to measure all of the above |
Alongside LifeSciBench, OpenAI reports gains on several in-house evaluations that pointedly are not externally judged: MedChemBench (27.5% vs 25.1% for GPT-5.5), GeneBench (21.6% vs 20.4%, with 31% fewer tokens), and LabWorkBench (63.2% vs 55.8% on wet-lab protocol support). It also shipped two Codex plugins — Life Sciences Research and Life Sciences NGS Analysis — to give the reasoning model an execution layer, echoing the agentic-tooling trend behind Claude Scientific Skills and DeepMind’s Co-Scientist.
Crucially, GPT-Rosalind is not an autonomous “AI scientist.” It’s positioned as a reasoning layer for human researchers, gated behind a trusted-access research preview — the opposite design philosophy to closed-loop self-driving-lab efforts.
How LifeSciBench compares to the competition
There are two competitions to track here: other life-science benchmarks, and other models/labs being measured.
vs. other life-science benchmarks
LifeSciBench enters a field that’s been building toward exactly this for two years. The key rivals:
| Benchmark | Builder | Format | Scale | Niche |
|---|---|---|---|---|
| LifeSciBench | OpenAI | Free-response, rubric-graded | 750 tasks, 19,020 criteria | End-to-end research judgment across 7 workflows |
| LAB-Bench | FutureHouse (2024) | Multiple-choice | ~2,457 questions, 8 categories | Foundational skills: LitQA, FigQA, ProtocolQA, SeqQA, cloning |
| BixBench | FutureHouse + ScienceMachine (2025) | Open-ended Jupyter analysis | 53 capsules / 296 questions | Real bioinformatics data analysis |
| BiomniBench | Phylo (2026) | Trace-based (grades process) | — | Catches silent failures in the analysis trace |
| HLE / ChemBench / BioCoder | Various | MCQ / coding | — | Knowledge frontier, chemistry, code generation |
What genuinely differentiates LifeSciBench:
- Free-response over multiple-choice. LAB-Bench’s MCQ format is reproducible and cheap to grade but can’t capture whether a model would say the right thing to a colleague. LifeSciBench’s rubric-graded free text is closer to reality — at the cost of far more expensive grading.
- End-to-end workflows, not isolated skills. LAB-Bench tests literature recall, figure reading, sequence manipulation as separate subtasks; LifeSciBench bundles them into multi-step, decision-oriented problems.
- Construction scale. 173 authors + 453 reviewers is a larger expert footprint than most academic benchmarks carry.
- The trade-off: BixBench and especially Phylo’s BiomniBench push on something LifeSciBench mostly doesn’t — iterative, tool-executing agentic analysis with process-level grading. LifeSciBench is largely single-turn. Its own authors concede it doesn’t capture the dynamics of live, multi-round research.
vs. other models and labs
The uncomfortable framing OpenAI can’t fully escape: this is an OpenAI benchmark, scored by OpenAI, used to demonstrate an OpenAI model. LifeSciBench earns real credit for being externally expert-judged on task quality — that’s more than most vendor benchmarks do. But the companion evals (MedChemBench, GeneBench, LabWorkBench) are in-house, none of the model scoring has been independently reproduced, and the model comparison includes Gemini 3.1 Pro and Grok 4.3 but omits Claude. Read the absolute numbers as internal progress signals, not a settled cross-lab ranking.
Zoom out and LifeSciBench is one move in a crowded race to define — and win — “AI for science.” The benchmarkers (FutureHouse, Phylo, ScienceMachine) overlap with the agent-builders, and the agent-builders (DeepMind’s Co-Scientist, Phylo’s Biomni Lab, Flagship’s Lila Sciences, Medra.ai) are chasing the same prize from the “autonomous scientist” end while OpenAI chases it from the “expert reasoning layer” end. Even the structure-and-design players we’ve covered — from Isomorphic Labs’ IsoDDE to Amazon Bio Discovery — need exactly this kind of evaluation to prove their tools actually help.
What to watch
- Self-grading is the structural caveat. LifeSciBench’s external task-quality review is genuinely better practice than most. But OpenAI still chose the tasks, ran the scoring, and picked the comparison set. Independent re-scoring — ideally including Claude and other frontier models — is the thing to wait for.
- The absolute numbers are humbling. A 36.1% overall pass rate, 30% on analysis and design, 14.8% on numeric answers — these are early-innings scores. The benchmark is far from saturated, which is healthy, but it also means “frontier AI for life science” is still assistive, not transformative, on hard tasks.
- Artifacts are the real frontier. The text-only-to-artifact cliff (45% → 28%) is the most scientifically important gap. Until models reliably read figures, sequence files and structures and act on them, they remain limited collaborators for data-rich work.
- Benchmark ≠ research impact. OpenAI says this explicitly: strong LifeSciBench performance signals task-level capability, not downstream discovery. The promised next step — measuring whether these models actually accelerate live R&D over long horizons — is where the claim will ultimately be tested.
- Small subcategories invite over-reading. The flashy Scientific Communication jump (56% → 71%) rests on just nine tasks. Treat per-category swings as directional, not definitive.
Bottom line
LifeSciBench is the most carefully built life-science AI benchmark to date — a serious attempt to grade research judgment rather than biology trivia, with an expert-authored rubric design that other benchmarks should borrow. Its results tell a measured story: GPT-Rosalind is a real step up from GPT-5.5, especially at synthesis, translation and handling uncertainty, while remaining weak on analysis, design, exact outputs and anything artifact-heavy — and Gemini 3.1 Pro still wins a large share of tasks outright. The benchmark’s biggest limitation is the one OpenAI can’t design away: it’s a vendor’s measuring stick for a vendor’s model. The most useful thing the rest of the field can do is take LifeSciBench’s methodology seriously — and run it independently, with every frontier model in the room.
Related on Labcritics
- OpenAI Enters the AI-Bio Arms Race with GPT-Rosalind
- Google DeepMind’s Co-Scientist Graduates from Research Demo to Nature Paper
- Claude Scientific Skills: Turning AI Agents into Research Powerhouses
- Amazon Bio Discovery: Rewiring the Antibody Discovery Pipeline
- Isomorphic Labs’ New Drug Design Engine Promises to Outdo AlphaFold 3
External sources & further reading
- OpenAI — Introducing LifeSciBench (openai.com, Jun 17, 2026) and the LifeSciBench preprint
- OpenAI — Introducing GPT-Rosalind (Apr 2026) and Introducing new capabilities to GPT-Rosalind (Jun 2026)
- LAB-Bench: Measuring Capabilities of Language Models for Biology Research — FutureHouse / arXiv (2024)
- BixBench: a Benchmark for LLM-based Agents in Computational Biology — FutureHouse + ScienceMachine / arXiv (2025)
- Evaluating AI Agents in Biology (BiomniBench) — Phylo (2026)
- Reporting from MarkTechPost, RDWorld, and TechTimes on the GPT-Rosalind update and LifeSciBench leaderboard